週二安安,今天進到了 SRE 方法論的第三條:監控系統,這裡是今天讀的原文出處:Introduction,話不多說,我們開始囉!
書中提到一個監控系統裡會有三類輸出:
如果對應到現今 GCP 提供的服務,會像下面這樣:
在 Alerting 的部分,在 GCP 上我有兩個設置的方法,第一個是從 Alerting 的頁面去 Create Policy,裡面可以選擇各種 Metric 來當作標準。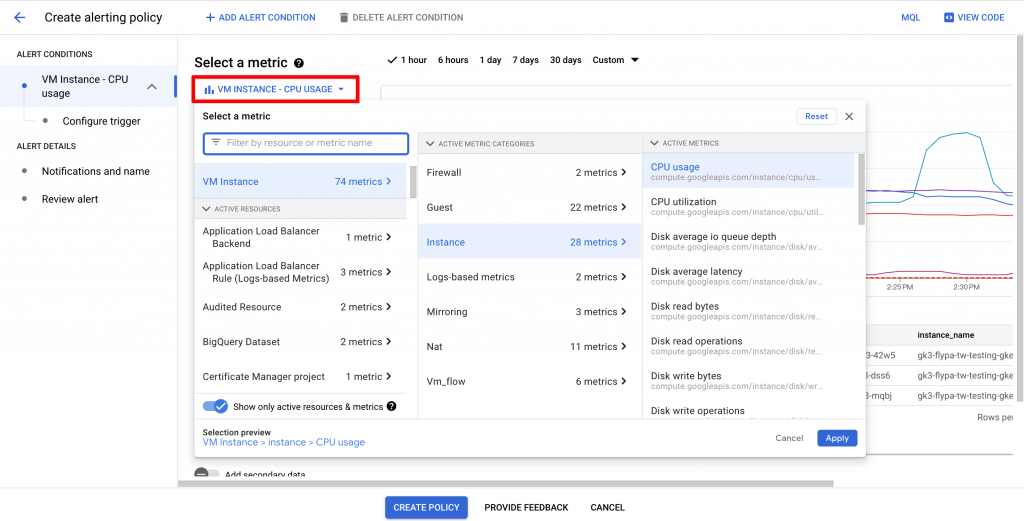
第二種方法是透過 Logging 介面,先篩選出需要的 Log,並製作自定義的 Log-based Alerts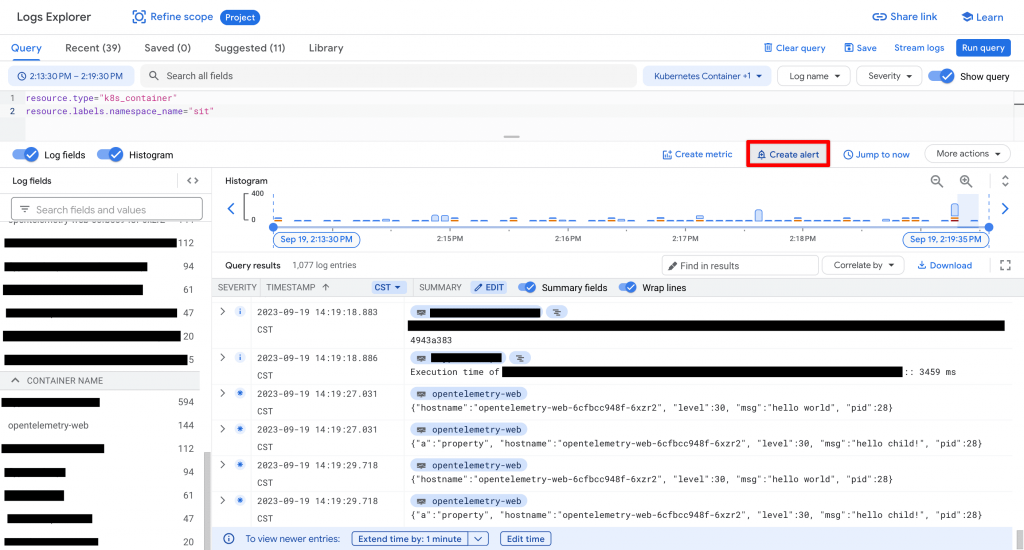
目前對 Error Reporting 的使用還不多,不過目前的規劃是會希望把 Error Reporting 串接 ClickUp(我們的文件服務),觸發 ClickUp 的創建文件通知給開發團隊!讓開發團隊可以依照一張一張卡片去修復,並記錄相關事故報告。
由於 ClickUp 也有內建通知管道,只要修改或移動,也都能通知到團隊,真的很方便!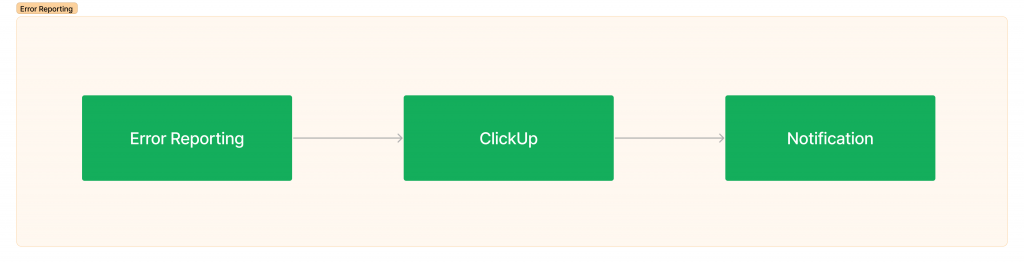
真心覺得 Logging 很好用!!!雖然上面提到如果沒有需要,其實可以不用特別去翻閱,不過由於現在我做的告警還沒有那麼完整,因此在 Logging 裡面瞎逛的時候,常常會有一些意外發現!
在使用的時候比較少直接使用上面那一個方框,雖然有提示詞可以使用很方便,不過由於這個專案的服務不算多,所以反而使用左側的選單會更快速的找到我想看的資料!
今天加上了一些目前有使用到的功能,不過在翻閱資料的時候也迸發了一些新的想法,可能之後也會應用在系統上,接下來是應急事件的處理!那麼就明天見拉!掰噗!
如果把這邊的概念疏理一下,應該就是
如果平台可以自己解決就平台自己解決。
如果平台不能解決就分類問題成:
* 緊急警報(Alert):立刻處理
* 工單(Ticket):依照SLO中的需求排單處理
處理完之後撰寫事故報告並且添加自動化程式讓平台未來可以自動化處理。
感謝整理 XD
如果把這邊的概念疏理一下,應該就是
如果平台可以自己解決就平台自己解決。
如果平台不能解決就分類問題成:
* 緊急警報(Alert):立刻處理
* 工單(Ticket):依照SLO中的需求排單處理
處理完之後撰寫事故報告並且添加自動化程式讓平台未來可以自動化處理。

